
How to recode 40.000 brand mentions without training data using a levenshtein distance matrix in R.

If you ever had to deal with open-ended questions in online-interviews you definitely run into the problem of quantifing them. The given responses of the interviewees are often full of typos and mismatches needed to get recoded properly, even worse, most brands have various aliases you have to consider into your analysis. I’ll show you how to correctly classify 95%-99% of that given answers, without even using a Machine Learning Model or Deep Learning.
Click-Bait disclaimer: This method only works well for special recoding tasks like the following. 🙂
The Problem
Quantifing the unaided brand awareness/recall of twelve german banks by recoding the responses of ~25.000 online-interviews. (Anyone interested in advertising/brand metrics: Link). Every person (“ID”) could recall up to 8 brands resulting in 40.000 answers! Here’s what the original output looks like:

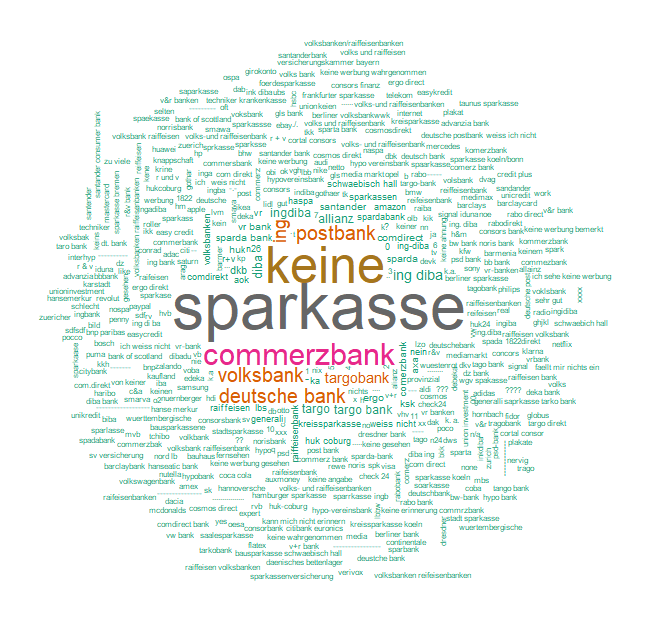
Pay close attention to the different spellings of “sparkasse” or “commerzbank” and the different aliases of “IngDiba”. A wordcloud of the 1000 most frequent responses shows that there is a only handful of recurring answers, although they account for 60% of all mentions!
Possible Solutions
You basically have 3 options to get the job done:
- Hiring a low paid worker
Pro: No data skills required. Still the most common solution in most companies.
Con: Error prone. No documentation. No Transparency. Subjective. - Deep Learning Model
Pro: Get rid of the problem once and for all and sell your DL-Model!
Con: No Training Data. Budget?! Maybe overdone. - Levenshtein distance matrix & simple heuristics
Pro: Easy setup. Clear Rules. Transparent.
Con: Works only for special tasks.
This post ist, obviously, focussing on the third solution but i’m very curious if a deep learning model can be applied for this task. (Don’t forget, that there is no training data!)
Basically you have to follow these five steps:
- Create a dictionary with aliases.
- Format your strings (Get rid of special characters, trailings spaces, etc.).
- Reduce your data to unique answers.
- Create a “big” levenshtein distance matrix.
- Classify anwers with simple heuristics + LDM.
Step One: Create a Dictionary with aliases
First of all you have to generate a dictionary with all desired brand names of interest including possible alises. For example the brand “Deutsche Bank” can be abbreviated as “DB” or bank “Ing-Diba” will often be written as “ing” or “diba”. You need a bit of domain knowledge here to make it easier for the LDM. A dictitionary can look like this:
require(dplyr)
require(tidyr)
require(purrr)
require(forcats)
require(caret) # only for confusion matrix
Sys.setenv(LANG = "de_DE.UTF-8") # Set Language to German
#Creating Dictionary with aliases with banks of interest
dict <- list("Deutsche_Bank" = c("deutsche bank", "db"),
"Commerzbank" = c("commerzbank"),
"Postbank" = c("postbank"),
"Hypovereinsbank" = c("hypo vereinsbank", "hypo", "hypobank"),
"Targobank" = c("targobank", "targo"),
"Sparkasse" = c("sparkasse", "kreissparkasse", "stadtsparkasse"),
"Volks_und_Raiffeisenbank" = c( "v+r", "volksbank", "raiffeisenbank", "volks und raiffeisenbank"),
"Ingdiba" = c("ing diba", "ing", "ingdiba", "diba"),
"Santander"= c("santander"),
"Spardabank" = c("sparda-bank", "sparda"),
"Union_Invest" = c("union invest", "union"),
"N26" = c("n26"),
"No_answer" = c("keine", "keine ahnung"))
We are tweaking our dictionary by adding a “Don’t know / None” brand, because many people in an online-interview won’t remember any brand just didn’t want to left the field empty.
Step Two: Format your strings
Luckily we are only interested in brand names, so we dont’t have to do an advanced stemming and lemmatization of our responses.
To speed up the LDM function we just have to reduce the number of unique words removing/replacing:
- Trailing Spaces
- Special characters and umlauts
- Uppercases
#Preprocess to get unique answers
df <- pivot_longer(df, starts_with("f06"), values_to = "answer") #Transform to Long-Format
df <- filter(df, answer != "") #Remove blank answers
string_format <- function(x) {
x <- gsub("^\\s+|\\s+$", "", x) # remove trailing spaces
x <- tolower(x) # to lower
x <- gsub("ä","ae",x) # remove german "Sonderlaute"
x <- gsub("ü","ue",x) # remove german "Sonderlaute"
x <- gsub("ö","oe",x) # remove german "Sonderlaute"
x <- gsub("ß","ss",x) # remove german "Sonderlaute"
x <- gsub("|","",x) # remove special characters
return(x)
}
df$answer <- string_format(df$answer) #Applying functionStep Three: Reduce your data to unique answers.
Hence duplicated answers will have the same distance in our LDM, it’s time to get rid of them. Let’s preserve the frequencies of given answers to adjust our classifaction evaluation later on with a bit of dplyr.
df_unique <- df %>%
group_by(answer) %>%
summarise(n = n()) %>%
arrange(desc(n)) %>%
mutate(frq = n / sum(n)*100) %>%
mutate(frq_sum = cumsum(frq))
head(df_unique)This leads to ~3000 unique answers in total. Here’s a snapshot of the first 40 answers in descending order by frequency, indicating that many brands are misspelled or appearing under aliases.

Step Four: Create a “big” levenshtein distance matrix.
But wait: What does the Levenshtein algorithm do? In brief, every word is checked on how many “deletions”, “insertion” or “subsitutions” of a character in a word are needed to transform it to the desired outcome, in this case our aliases. By default a deletion and an insertion “cost“a penalty of 1 point, while a substituion costs 2 points. (A substition is nothing else than a deletion following an insertion!).
Some examples:
- Deutzsche Bank -> Deutsche Bank (Deletion, 1 point)
- Deusche Bank -> Deutsche Bank (Insertion, 1 point)
- Deuzsche Bank -> Deutsche Bank (Substition, 2 points)
- Sparkasse -> Deutsche Bank (Multiple operations, 16 points)
Luckily the algorithm is already implemented in R (adist function) and you only need a bit of data wrangling to get the answer-alias combination with minimum distance.
dict_long <- unlist(dict) #Preprocess dict to vector
#Creating levenshtein distance matrix (ldm)
levenshtein <- function(answers, dict) {
#Creating levenshetein distance
df <- adist(answers, dict, costs = c("ins"=1, "del"=1, "sub"=2))
df <- as.data.frame(df)
colnames(df) <- dict # user friendly view
#Further decision making based on distance later on
cols <- c("min_distance", "col_index") # view result cols
df[, cols] <- NA # Init cols
for ( i in 1:nrow(df) ) {
df[i,"col_index"] <- which.min(df[i,!(colnames(df) %in% cols )])
df[i,"min_distance"] <- min(df[i,!(colnames(df) %in% cols )])
#df[i,"ldm"] <- if(!is.na(df[i,"col_index"])) {colnames(df[df$col_index[i]]) } else {NA}
}
df$ldm <- ifelse(!is.na(df["col_index"]), colnames(df)[df$col_index], NA )
df$answer <- answers # original answers
return(df)
}
ldm <- levenshtein(df_unique$answer, dict_long)This simplified levenshtein distance matrix illustrates the main idea so that we can shortly discuss the benefits and drawbacks of the distance matrix for our given task:
- ** Dataframe***
Short idea, benefits, drawbacks
Step Five: Classify anwers with simple heuristics + LDM.
We will try different recoding approaches to benchmark our LDM classification vs. a (nearly perfect) manual recoding:
- Level 0: Exact case matching of aliases
- Level 1: Matching aliases pattern
- Level 2.1: LDM without a “cut”
- Level 2.2: LDM with a “cut” at a distance above 2
- Level 2.3: LDM with a “cut” based on character length.
- Level 3: LDM with a “cut” based on character length and matching pattern combined.
The performance of our approaches is measured by Specifity, Sensitivity and most important in this case: Accuracy.
Level 0 and 1: Exact case matching and pattern matching
Simple ifelse-loops and some “grep” will get the job done to match by (exact) alias pattern:
#Level 0: Exactmatching
df_unique$lvl_0 <- NA
for(i in 1: length(dict_long)) {
df_unique$lvl_0 <- ifelse(df_unique$answer == dict_long[i], dict_long[i],
df_unique$lvl_0 )
}
#Level 1: Contains Word matching
df_unique$lvl_1 <- NA
for(i in 1: length(dict_long)) {
df_unique$lvl_1 <- ifelse(grepl(dict_long[i], df_unique$answer), dict_long[i],
df_unique$lvl_1 )
}Level 2.1- 2.3: Classification by distance with levenshtein
It’s time to finally do the classification with our LDM (object: ldm).
#Level 2.1 - 2.3: LDM and LDM with Cut 2, and Cut depending on string length
#Binding to df
df_unique <- left_join(df_unique, ldm)
df_unique$lvl_2_1 <- df_unique$ldm
# Setting specific distance cuts, so classification is stopped, when dist is to far
df_unique$lvl_2_2<- ifelse(df_unique$min_distance<= 2, df_unique$ldm, NA)
df_unique$lvl_2_3<- ifelse( (df_unique$min_distance <= 2 & nchar(df_unique$answer) >3) |
(df_unique$min_distance <= 4 & nchar(df_unique$answer) >=8) |
(df_unique$min_distance <= 6 & nchar(df_unique$answer) >=12), df_unique$ldm, NA)Level 3: Combining pattern matching and LDM
In the last step, we will combine the pattern matching approach (Level 1) with with the flexible LDM classification (Level 2.3).
# Level 3: Bringing levenshtein and Matching together
df_unique$lvl_3 <- ifelse(!is.na(df_unique$lvl_1), df_unique$lvl_1, df_unique$lvl_2_3)Benchmarking
Let’s have a closer look on the results:

The combination of simple rules and levensthein leads to an Accuracy of nearly 99%!
If you look into the details, you will notice, that only “Volks- und Raiffeisenbank” is working “poorly” with 95% ACC, other brand names are working perfectly:

In brief: some ideas for further optimisations:
- Enhanced levenshtein algorithm
- Multiple Recalls in one cell
- Fine tuning of heruistics and aliases
Thanks for reading! Excuse the unpretty stlying and tables -> it’s hard to get into the details with two kids. 🙂
You can find the full dataset and complete R-Syntax on github: https://github.com/Vogelweide1985/12_recode_brand_names